
Column and Row Based Database Storage
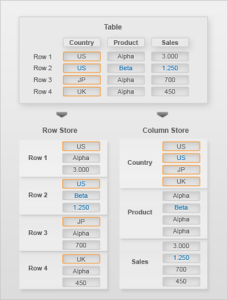
- Row-Based Database Storage:
- The data sequence consists of the data fields in one table row.
- Column-Based Database Storage:
- The data sequence consists of the entries in one table column.
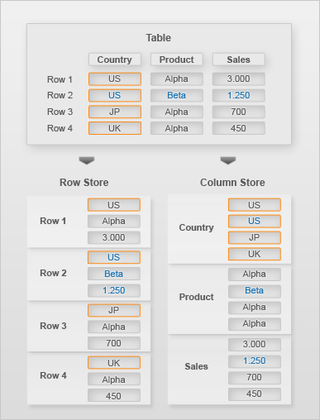
Conceptually, a database table is a two-dimensional data structure with cells organized in rows and columns. However, computer memory is organized as a linear sequence. For storing a database table in linear memory, two options can be chosen (row based storage or column based storage). Row based storage stores a sequence of records that contain the fields of one row in the table. In column based storage, the entries of a column are stored in contiguous memory locations.
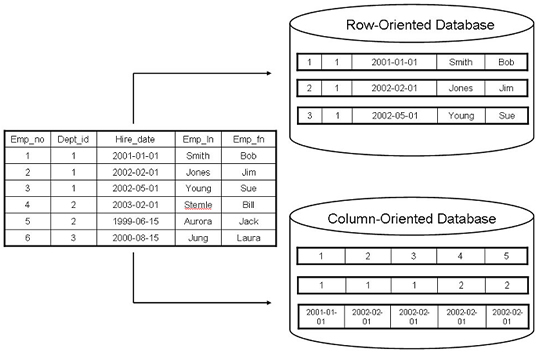
Row-based database systems are designed to efficiently return data for an entire row, or record, in as few operations as possible. This matches the common use-case where the system is attempting to retrieve information about a particular object. This is particularly useful for transactional systems that conduct large amounts of inserts, updates, and deletes of records.
Column-based database systems combine all of the values of a column together, then the values of the next column, and so on. Within this layout, any one of the columns more closely matches the structure of an index in a row-based system. The goal of a columnar database is to efficiently write and read data to and from hard disk storage in order to speed up performance of select queries. This is particularly useful for systems that conduct large amounts of analytics.
Row-based storage is recommended for transactional systems or when:
- • The table has a small number of rows, such as configuration tables.
- • The application needs to conducts updates of single records.
- • The application typically needs to access the complete record.
- • The columns contain mainly distinct values so the compression rate would be low.
- • Aggregations and fast searching are not required.
Column-based storage is recommended for analytical systems or when:
- • Calculations are executed on a single column or a few columns only.
- • The table is searched based on the values of a few columns.
- • The table has a large number of columns.
- • The table has a large number of records.
- • Aggregations and fast searching on large tables are required.
- • Columns contain only a few distinct values, resulting in higher compression rates.




 Appliance")