Business Rationale for NoSQL
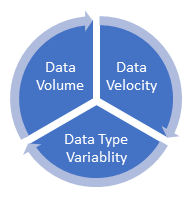 According to the book, “Making Sense of NoSQL”, by Dan McCreary and Ann Kelly, increases of data volume, data velocity, and data type variability within modern business organizations has created a high demand on conventional relational database management systems (RDBMS) and requires a new paradigm for organizations to remain effective. Organizations have been realizing that they now need to rapidly capture and analyze immensely large amounts of changing data that is being received in many different formats. Data volume and data velocity refer to the ability to process large data sets as they rapidly arrive. Data type variability refers to diversity in data types that don’t easily fit into structured database tables.
According to the book, “Making Sense of NoSQL”, by Dan McCreary and Ann Kelly, increases of data volume, data velocity, and data type variability within modern business organizations has created a high demand on conventional relational database management systems (RDBMS) and requires a new paradigm for organizations to remain effective. Organizations have been realizing that they now need to rapidly capture and analyze immensely large amounts of changing data that is being received in many different formats. Data volume and data velocity refer to the ability to process large data sets as they rapidly arrive. Data type variability refers to diversity in data types that don’t easily fit into structured database tables.
• Data Volume: Volume refers to the incredible amounts of data generated each second from social media, email, message, text documents, smart phones, sensors, photographs, video, etc. The vast amounts of data have become so large in fact that the data can no longer be stored and analyzed using traditional database technology. Now that data is generated by machines, networks, and human interaction, the amount of data to be analyzed is massive. We now use distributed systems, where parts of the data are stored in different locations and brought together by software. Collecting and analyzing this data is clearly an engineering challenge of immensely vast proportions. More sources of data with a larger size of data combine to increase the amount of data that must be analyzed. This is a major issue for those organizations looking to put that data to use instead of letting it just disappear.
• Data Velocity: Velocity refers to the speed at which vast amounts of data are being generated, collected and analyzed. Additional, velocity deals with the pace at which data flows in from sources like business processes, machines, networks and human interaction. And the flow of data is both continuous and massive in amount. Real-time data can help researchers and businesses make valuable & timely decisions that provide both strategic and competitive advantages, as well as a high return on investment (ROI). Not only must the data be rapidly analyzed, but the speed of transmission, and access to the data must also remain instantaneous. In the past, companies analyzed data using long-running batch processes. That paradigm worked well when the incoming data rate was slower than the batch processing rate and when the result was useful despite the delay in analysis execution. With new sources of data such as social, web, and mobile applications, the batch process paradigm has broken down. Now data is now streaming into servers in a real-time, continuous fashion and the result is only useful if data is immediately analyzed with very little delay.
• Data Type Variability: Variability refers to the many sources and types of data both structured and unstructured. In the past, data was managed primarily within spreadsheets and relational databases. Now data comes in the form of emails, text, photo, audio, video, web, GPS data, sensor data, relational databases, documents, messages, pdf, flash, etc. Data structures have changed to lose its rigid structure and hundreds of data formats are now being implemented. Organizations no longer have control over the input data format. Structure can no longer be imposed like in the past in order to keep control over the analysis. Organizations that want to capture and report on exception data struggle when attempting to use rigid database schema structures imposed by traditional relational database management systems. More and more, data being created and being analyzed is of the unstructured variety. New and innovative technologies are now allowing both structured and unstructured data to be harvested, stored, and processed simultaneously.
Core Themes of NoSQL Databases
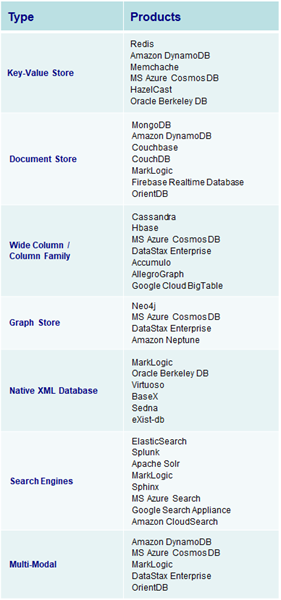
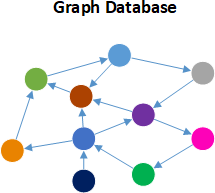
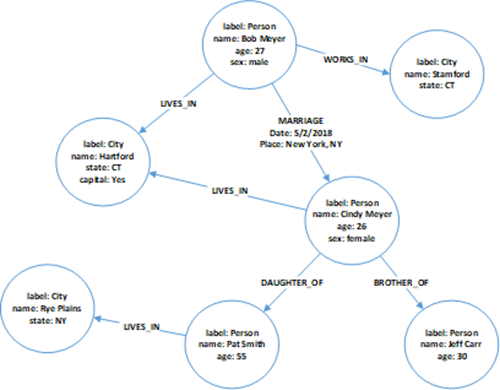
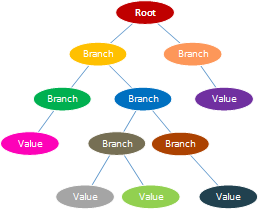
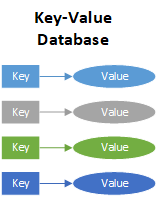
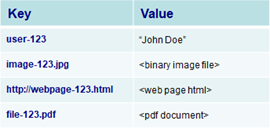
• Multiple data formats: NoSQL databases store and retrieve data from many formats: key-value stores, graph stores, wide column / column family stores, document stores, & search engines.
• Free of table joins: NoSQL databases allow for extraction of data using simple interfaces without the use of joins between tables.
• Free of pre-defined schema: NoSQL databases allow users to place data into a file folder and then query the data without defining a data schema.
• Distributed processing: NoSQL databases can use more than one or multiple computer processors in order to execute.
• Horizontal scaling / scaling out: NoSQL databases have direct increases of system performance with the addition of computer processors.
• Design alternatives: NoSQL databases offer multiple options to a traditional single method of storing, retrieving, and manipulating data.
• High performance: NoSQL database are optimized for specific data models and access patterns that enable higher performance than trying to accomplish similar functionality with relational databases.
• Rapid implementations: NoSQL databases generally provide flexible data schema that enable faster and more iterative development.
Common Misconceptions of NoSQL Databases
• NoSQL is all not about the SQL query language: NoSQL databases are not applications that utilize a language other than SQL. SQL as well as other query languages are used with NoSQL databases.
• NoSQL is not all about open source projects: Although many NoSQL database are built upon an open source model, commercial products use NoSQL concepts as well as open source initiatives.
• NoSQL is not only used in big data projects: Many NoSQL databases are driven by the inability of an application to efficiently scale when big data is utilized. While data volume and data velocity are important to NoSQL database implementations, NoSQL databases also focus on data type variability and the ability to rapidly implement solutions.
• NoSQL is not only used in cloud environments: NMany NoSQL databases do reside in cloud environments to take advantage of the cloud’s ability to rapidly scale. But NoSQL databases can run in both the cloud as well as on-premise data centers.
• NoSQL is not all about a clever use of memory and SSD: Many NoSQL databases do focus on the efficient use of computer memory and/or solid-state disks (SSD) to increase performance. While important, NoSQL databases can run on standard commodity hardware.
• Design alternatives: NoSQL databases offer multiple options to a traditional single method of storing, retrieving, and manipulating data.
• NoSQL is not just a few products: More and more NoSQL databases are constantly being developed. And existing NoSQL databases are constantly being enhanced to included additional functionality.
• NoSQL databases are not just about solving one problem: While many NoSQL databases have only been developed using one type of database model, many other NoSQL databases are multi-modal and can solve multiple types of problems.

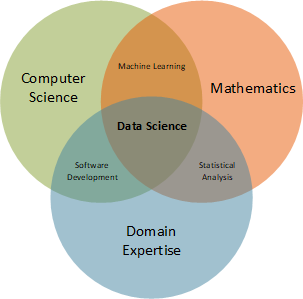





 Recently,
Recently,