About
Posts
Business Intelligence
Oracle BI
Business Objects
Data Warehousing
Data Warehouse Appliance
Master Data Management
Methodology / Framework
NoSQL
Virtualization
Microservices
Portfolio Items
Databases
Data Warehousing
Data Warehouse Appliance
Vendors and Products
Business Intelligence
NoSQL
Machine Learning
Master Data Management
Center of Excellence (COE)
Common Data Model
Cloud
Jobs
ZipRecruiter Job Search
Indeed Job Search
BI-Insider Job Board
Useful Websites
Contact Info
Search
Menu
Menu
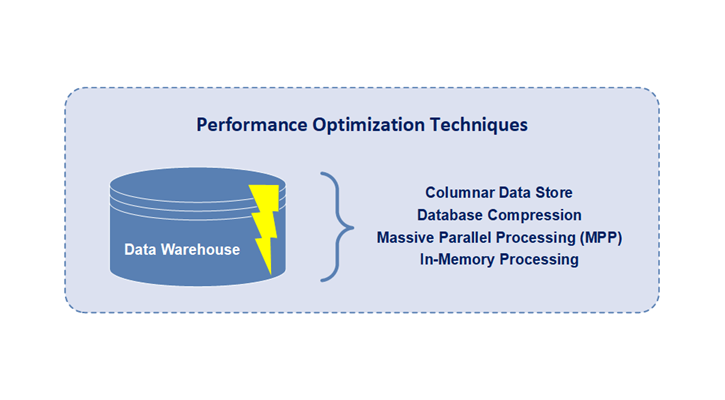
Techniques of Data Warehouse Performance Optimization
NoSQL Databases – An Overview
SAP HANA Platform – Technical Overview
Benefits of a Data Warehouse
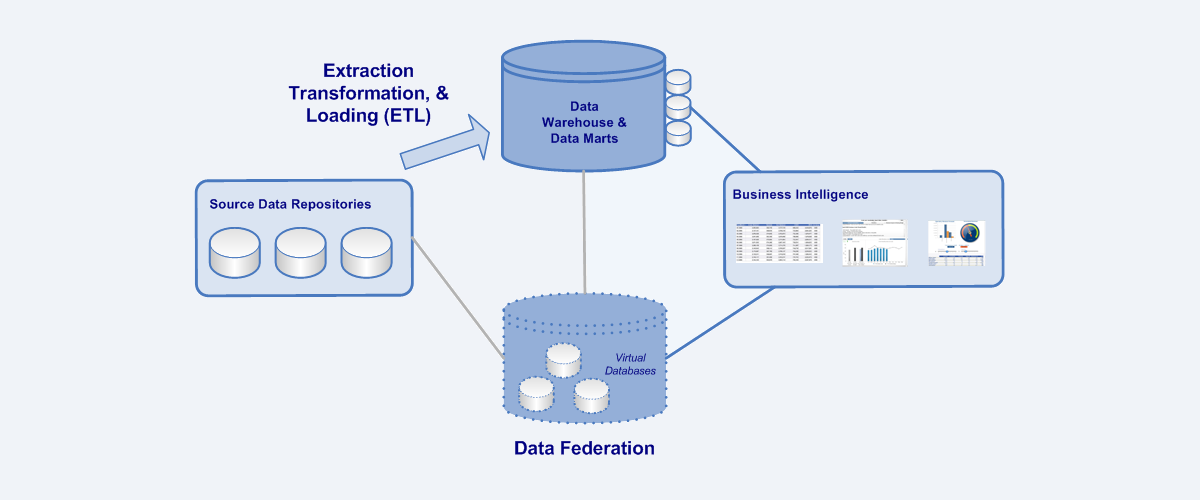
Data Integration Techniques (ETL and Data Federation)
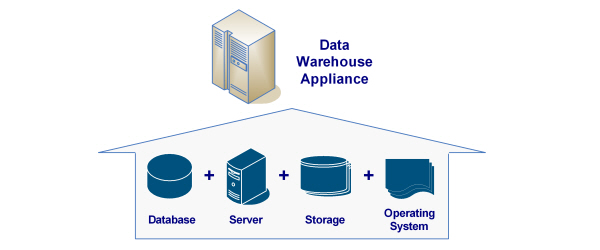
Data Warehouse Appliance Vendors and Products
Modeling Slowly Changing Dimensions in Data Warehouses
Basic Concepts of EDW and Data Marts
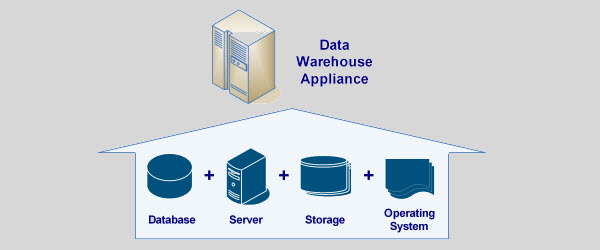
Overview of a Data Warehouse Appliance
Scroll to top
Facebook Like Button for Dummies