
Document NoSQL Database
Document NoSQL Database
 A document database, also called a document store or document-oriented database, is a NoSQL database used for storing, retrieving, and managing semi-structured data. Unlike traditional relational database management systems (RDBMS), the data model in a document database is not structured in a table format of rows and columns. A document database uses documents as the structure for storage and queries. Subsequently a document database aggregates data from documents and stores the documents a searchable and organized format. The schema of document databases can vary, providing far more flexibility for data modeling than RDBMS. In this case, the term “document” may refer to a MS Word, MS Excel, MS PowerPoint or Adobe PDF document but is commonly a block of extensible markup language (XML) or javascript object notation (JSON) code and values. Instead of columns with names and data types that are used in RDBMS, a document contains a description of the data type and the value for that description. Each document stored within a document database can have the same or different structure.
A document database, also called a document store or document-oriented database, is a NoSQL database used for storing, retrieving, and managing semi-structured data. Unlike traditional relational database management systems (RDBMS), the data model in a document database is not structured in a table format of rows and columns. A document database uses documents as the structure for storage and queries. Subsequently a document database aggregates data from documents and stores the documents a searchable and organized format. The schema of document databases can vary, providing far more flexibility for data modeling than RDBMS. In this case, the term “document” may refer to a MS Word, MS Excel, MS PowerPoint or Adobe PDF document but is commonly a block of extensible markup language (XML) or javascript object notation (JSON) code and values. Instead of columns with names and data types that are used in RDBMS, a document contains a description of the data type and the value for that description. Each document stored within a document database can have the same or different structure.
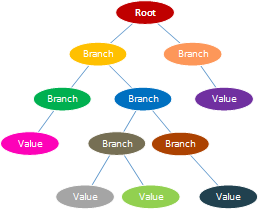 Document databases use a tree-like structure that begins with a root node. And beneath the root node, there is a sequence of branches, sub-branches, and values. Subsequently, each branch has a related path expression that shows to navigate from the root of the tree to any given branch, sub-branch, or value. Most document stores group documents together within document collections. And these collections are similar in look and feel to the directory structure in a Windows or UNIX/Linux file system. Document collections can be used to navigate document hierarchies, logically group similar documents, and to store business rules including permissions, indexes, and triggers. Additionally, collections can contain other collections.
Document databases use a tree-like structure that begins with a root node. And beneath the root node, there is a sequence of branches, sub-branches, and values. Subsequently, each branch has a related path expression that shows to navigate from the root of the tree to any given branch, sub-branch, or value. Most document stores group documents together within document collections. And these collections are similar in look and feel to the directory structure in a Windows or UNIX/Linux file system. Document collections can be used to navigate document hierarchies, logically group similar documents, and to store business rules including permissions, indexes, and triggers. Additionally, collections can contain other collections.
Documents within document databases are identified using a unique key, which contains a simple identifier. The key usually contains either a string, a URI, or a path. And the key can be used to retrieve the document from the database. Typically, the database retains an index on the key to speed up document retrieval. And sometimes, the key is used to create or insert the document into the database.
are identified using a unique key, which contains a simple identifier. The key usually contains either a string, a URI, or a path. And the key can be used to retrieve the document from the database. Typically, the database retains an index on the key to speed up document retrieval. And sometimes, the key is used to create or insert the document into the database.
A key advantage of a document database is that all values within the document are automatically indexed when a new document is insert into the database. That means that every value within the document can be searched upon. This also means that if a user knows any property of the document, all documents with the same property can be easily retrieved. And even if the document structure is complex, a document store search provides an easy way to select either an entire document or a sub-set of a document. Additionally, document database searches can tell the user whether the search item is included within a document as well as the search items exact location utilizing the document path.
To add additional types of data to a document database, there is no need to modify the entire database schema as is with a RDBMS. Data can simply be added by adding objects to the database. Further document databases utilize internal structure within documents in order to extract metadata that the database engine uses for further optimization and query performance. Unlike traditional RDBMS, some document databases prioritize write availability over strict data consistency. This ensures that writes will always be fast even if there is a failure in one portion of the hardware or network.

Leave a Reply
Want to join the discussion?Feel free to contribute!