Apache Cassandra – NoSQL Database
Apache Cassandra is is a wide column column / column family NoSQL database management system with a distributed architecture.
About Apache Cassandra
Apache Cassandra is a massively scalable, open-source NoSQL database management system. Cassandra was first created at Facebook and later released as an open-source project in July 2008. Cassandra is lightweight, non-relational, and largely distributed. Further, Cassandra enables rapid, ad-hoc organization and analysis of extremely high volume of data and disparate data types. That’s become more important in recent years, with the advent of Big Data and the need to rapidly scale databases in the cloud. Cassandra is among the NoSQL databases that have addressed the constraints of previous data management technologies, such as conventional relational database management system (RDBMS).
Strengths of Apache Cassandra are horizontal scalability, a distributed architecture, a flexible approach to schema definition, and high query performance.
Apache Cassandra stores data in tables, with each table consisting of rows and columns. Cassandra Query Language (CQL) is the tool within Cassandra to query the data stored in tables. Cassandra’s data model is based around and optimized for large read queries. Additionally, Cassandra does not support transactional data modeling intended for relational databases (i.e. normalization). Rather, data is de-normalized within Cassandra and queries can only be conducted for one table at a time. For this reason, the concept of joins between tables within Cassandra does not exist. Having de-normalization of data enables Cassandra to perform well on large queries of data.
Why Organizations Are Using Cassandra
Apache Cassandra is ideal for analysis of large amounts of structured and semi-structured data across multiple datacenters and the cloud. Moreover, Cassandra enables organizations to process large volumes of fast moving data in a reliable and scalable way. Cassandra quickly stores massive amounts of incoming data and can handle hundreds of thousands of writes per second. Fundamentally, Cassandra offers rapid writing and lightning-fast reading of data.
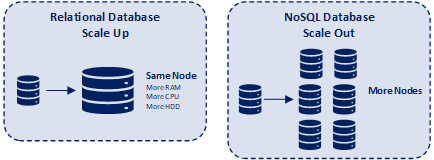
Apache Cassandra is different from conventional relational databases when it comes to scaling. A relational database typically scales-up by using more computing power (memory, processing, hard disk space) to power the database instance. In contrast, Cassandra is built to scale-out and be available across multiple regions, data centers, and/or cloud providers. Cassandra scales by adding additional nodes to its configuration.
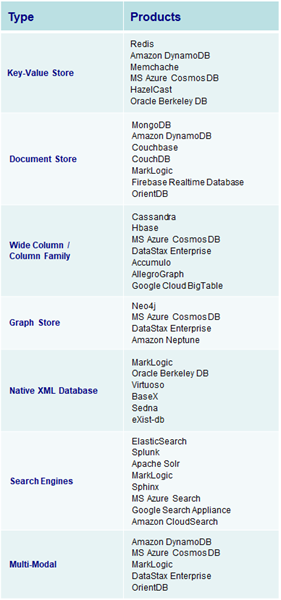
Wide Column / Column Family Database
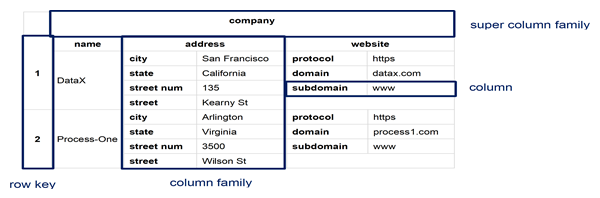
Apache Cassandra is a wide column column / column family NoSQL database, and essentially a hybrid between a key-value and a conventional relational database management system. Wide column / column family databases are NoSQL databases that store data in records with an ability to hold very large numbers of dynamic columns. Moreover, its data model is a partitioned row store with tunable consistency. Columns can contain null values and data with different data types. In addition, data is stored in cells grouped in columns of data rather than as rows of data. Columns are logically grouped into column families. Column families can contain a virtually unlimited number of columns that can be created at run-time or while defining the schema. And column families are groups of similar data that is usually accessed together. Additionally, column families can be grouped together as super column families.

The basis of the architecture of wide column / column family databases is that data is stored in columns instead of rows as in a conventional relational database management system (RDBMS). And the names and format of the columns can vary from row to row in the same table. Subsequently, a wide column database can be interpreted as a two-dimensional key-value. Wide column databases do often support the notion of column families that are stored separately. However, each such column family typically contains multiple columns that are used together, like traditional RDBMS tables. Within a given column family, all data is stored in a row-by-row fashion, such that the columns for a given row are stored together, rather than each column being stored separately.
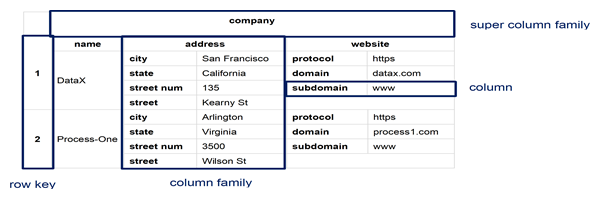
Since wide column / column family databases do not utilize table joins that are common in traditional RDMS, they tend to scale and perform well even with massive amounts of included data. And databases with billions of rows and hundreds or thousands of columns are common. For example, a geographic information systems (GIS) like Google Earth may a row ID for every longitude position on the planet and a column for every latitude position. Thus, if one database contains data on every square mile on Earth, there could be thousand of rows and thousands of columns in the database. And most of the columns in the database will have no value, meaning that the database is both large and sparsely populated.
Cassandra Query Language (CQL)
Included within Apache Cassandra is the Cassandra Query Language (CQL). CQL is a simple interface for accessing Cassandra that is similar to the more common Structured Query Language (SQL) used in relational databases including Oracle, SQL Server, MySQL and Postgres. CQL and SQL share the same abstract idea of a table constructed of columns and rows. Moreover, CQL supports standard data manipulation commands including Select, Insert, Update, and Delete. The main difference from SQL is that CQL does not support joins, subqueries, or aggregations (i.e. group by).
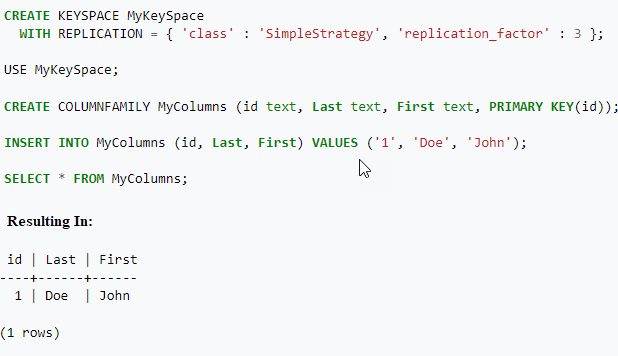
When Apache Cassandra was originally released, it featured a command line interface for dealing with directly with the database. Manipulating data this way was cumbersome and required learning the details of the Cassandra application programming interface (API). Subsequently, the Cassandra Query Language (CQL) was created to provide the necessary abstraction to make CQL more usable and maintainable.
Distributed Architecture
A distributed architecture means that Apache Cassandra can and does typically run on multiple servers while appearing to users as a unified whole. Apache Cassandra databases easily scale when an application is under high stress. The distribution of processing also prevents data loss from any given datacenter’s hardware failure. Apache Cassandra can, and usually does, have multiple nodes. A node represents a single instance of Apache Cassandra. These nodes communicate through a process of computer peer-to-peer communication. There is little point in running Cassandra as a single node, although it is very helpful to do so to while you get up to speed on how the application works. But to get the maximum benefit out of Cassandra, you would run Apache Cassandra on multiple machines within multiple data centers.
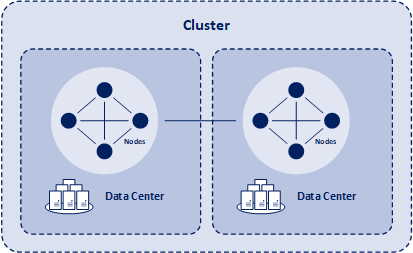
Node: The location of the processing and data. It is the most basic component of Apache Cassandra. It can be thought of as a single server in a rack.
Data Center: Either a physical collection or a virtual collection of nodes.
Cluster: Clusters comprise one or more data centers. Clusters usually span multiple different physical locations.
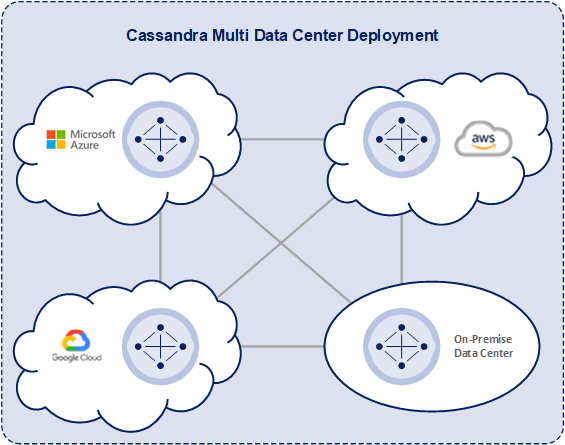
The distributed nature of Apache Cassandra makes it more resilient and able to perform well with large loads. Apache Cassandra makes it easy to increase the amount of data it can manage. Because it’s based on nodes, Cassandra scales horizontally, using lower commodity hardware. To increase the capacity, throughput, or power, just increase the the number of nodes associated with the installation. In addition, Cassandra is deployment agnostic as it can be installed on premise, a cloud provider, or multiple cloud providers. Cassandra can use a combination of data centers and cloud providers for a single database.





 Recently,
Recently,