
Data Vault Data Model for EDW
The Data Vault data model provides an evolution in the way that enterprise data warehouses (EDW) are designed, constructed, and deployed. Moreover, Data Vault provides a new and powerful way to model data within an enterprise data warehouse (EDW) that is more scalable, extensible, and auditible than conventional modeling techniques. It is an ideal modeling technique for EDW that either have a large volume of data, a large number of disparate data sources, a high degree of variety in the ingested data, or a large number of diverse information consumers. Fundamentally, the Data Vault is a hybrid data modeling technique that provides historical data representation from multiple sources designed to be resilient to environmental changes.
The Data Vault model provides a method of looking at historical data that deals with issues such as auditing, tracing of data, loading speed and resilience to change as well as emphasizing the need to trace where all the data in the database came from. This means that every row in a data vault is accompanied by record source and load date attributes, enabling an auditor to trace values back to the source.
According to Dan Linstedt, creator of Data Vault data modeling, Data Vault is defined as:
The data vault is a detail oriented, historical tracking and uniquely linked set of normalized tables that support one or more functional areas of business. it is a hybrid approach encompassing the best of breed between 3rd normal form (3nf) and star schema. the design is flexible, scalable, consistent and adaptable to the needs of the enterprise. it is a data model that is architected specifically to meet the needs of today’s enterprise data warehouses.
Data Vault Tables
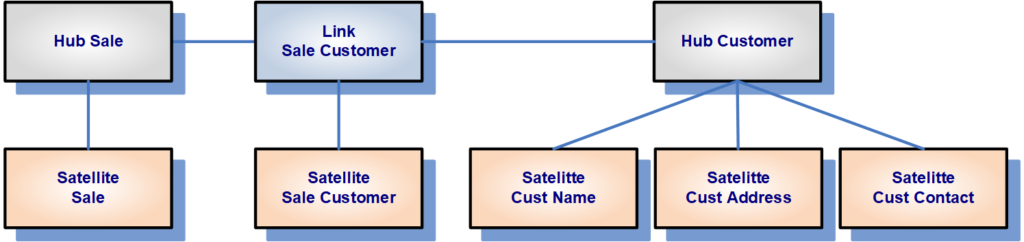
The Data Vault model is based upon three distinct table types which each table type serving a specific purpose:
- • Hub tables store a unique field for each business entity known as business key.
- • Link tables store relationships between hub tables.
- • Satellite tables store the attributes of the business key.
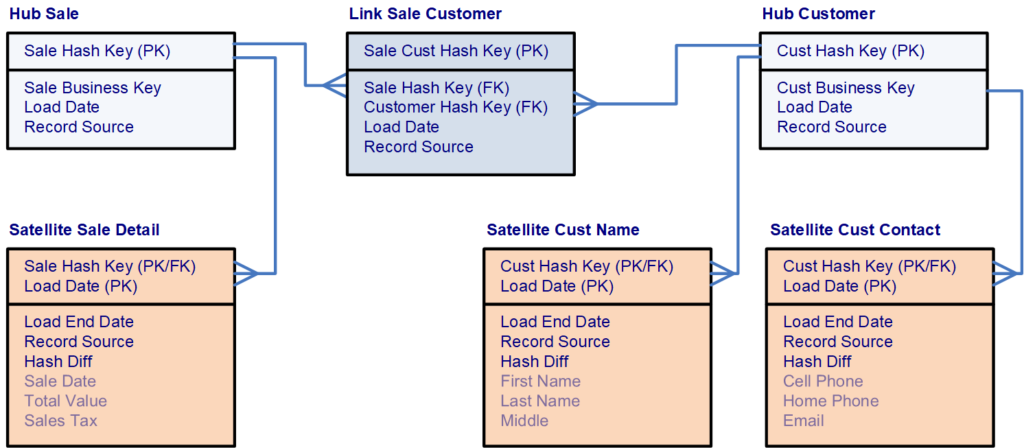
Hub Table: Consists of a list of unique business keys that represent a distinct way of identifying a business element as well as fields that describe the origin of the record. Additionally hub tables cannot contain any foreign key fields. Types of fields included in the hub table are:
- 1) Hash Key which serves as the primary key of the hub table in a hash format.
- 2) Load Date which includes the date time that the record was inserted into the hub table.
- 3) Record Source which includes the name of the data source from where the record originated.
- 4) Business Key which is the unique identifier of the business entity as a either a text or number value and can be more than one field in the table.
Link Table: Establishes relationships between business keys, contains foreign keys to hub tables, and includes fields about the relationship. A link table is therefore an intersection of business keys and contains the fields that represent the business keys from the related hub tables. The purpose of the link table is to capture and record the relationship of data elements at the lowest possible level of granularity. And a link table must have relationship with at least two hub tables. Types of fields included in link table are:
- 1) Hash Key which serves as the primary key of the link table in a hash format.
- 2) Foreign Keys which provide references to the primary hash key of related hub tables.
- 3) Business Keys which provide a copy of the business key value from the related hub tables.
- 4) Load Date which includes the date time that the record was inserted into the link table.
- 5) Record Source which includes the name of the data source from where the record originated.
Satellite Table:
Comprised of all the fields that describe a business entity or relationship and provide context at a given time or over a time period to either a hub or link. Satellite tables consist of foreign keys linking them to a parent hub table or link table, fields that describe the origin of the record, as well as a start and end dates fields. The structure and concept of a
satellite table is very much like a type 2 slowly changing dimension in a dimensional model. History of changes is stored within a
satellite table as well as change data capture (CDC) is conducted within a satellite table. Types of fields included in the satellite table are:
- 1) Parent Hash Key which provides a foreign key reference to a hub table and is one of two fields included in the primary key of the table.
- 2) Start Date which indicates the date and time that the satellite record starts being active and is the second of two fields included in the primary key of the table.
- 3) Record Source which includes the name of the data source from where the record originated.
- 4) Load End Date which indicates the date and time that the satellite record became inactive.
- 5) Extract Date which indicates the date and time that the records was extracted from the source system.
- 6) Hash Diff which is a hash value of all of the descriptive values of a record.
- 7) Descriptive Fields which are any fields that provide more detail about the entity.
Business Keys and Hash Keys
Business Key: A text value that must be a declared unique or alternate key constraint within the hub table. This means that only one distinct value can exist within the entire Hub table. The business key does not necessarily have to be just one field within the hub table. It can be a compound key made up of more than one column. Business keys are also included as non-unique fields within link tables. True business keys are not tied to any one source system and could be contained within multiple source systems. Examples of typical business keys include: account number, product code, customer number, employee id, invoice number, and order number.
Hash Key: One of the innovations within the latest version of the Data Vault model is the replacement of standard integer primary keys or surrogate keys with hash-based primary keys. This feature of the Data Vault model enables a Data Vault solution to be deployed either on a relational data management system (RDBMS) or on Hadoop systems. Hadoop systems do not have surrogate key generators like an RDBMS, but a unique MD5 hash value can be generated in Hadoop. With a hash key being used in Hadoop and a hash key being used in an RDBMS, tables can be logically joined.
Data Vault and Information Marts
The Data Vault layer within an EDW is normally used to store data and data is never deleted from the data vault unless there is a technical error while loading data. Additionally the Data Vault layer is not optimized for business intelligence and analytical use. Dimensional modeling is much more suited for this purpose. Subsequently, information marts contain dimensional models and are the source for data analytics. In order to be used by end-users, data contained in the data vault needs to be converted to a dimensional model and moved into related information marts. Dimension tables in information marts will then be sourced from data vault hub and related satellite tables. While fact tables in information marts will be sourced from data vault link and related satellite tables. Upon data being converted into dimensional models and moved into information marts, business intelligence tools including SAP Business Objects, Cognos, OBIEE, Tableau, SSAS, Power BI, & Qlik Sense can be used by end-users to conduct analytics on the data.
Summary
The best use for the Data Vault data model is within the enterprise data warehouse (EDW) of a complete business intelligence environment. Moreover, the Data Vault model is specifically designed for this purpose. And the Data Vault model is the ideal data modeling technique for databases that store large volumes of highly volatile data, contain a high degree of data variety, and contain data from multiple disparate sources.
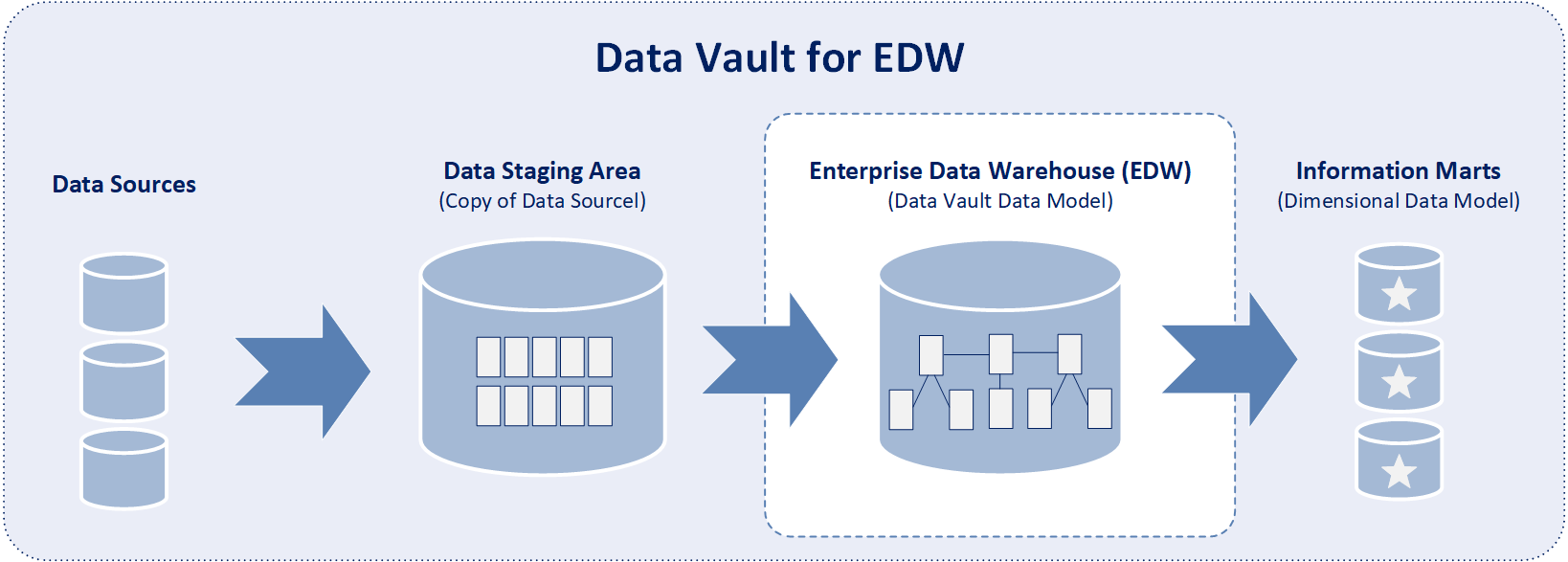
However, the Data Vault model is only one part of the complete Data Vault architecture which contains three layers:
- 1) Data Staging Area which contains a copy of source data.
- 2) EDW which is designed using the Data Vault model.
- 3) Information Marts which are designed using a dimensional model are the source of data for end-user analysis.

")
 Systems to Analytical (OLAP) Systems")