Graph NoSQL Database
Graph NoSQL Database
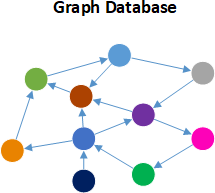 A graph database is a NoSQL database that organizes data as nodes, which are like records in a relational database, and relationships, which represent connections between nodes. Because the graph system stores the relationship between nodes, it can support richer representations of data relationships. Relationships are the key concept in graph databases, representing an abstraction that is not directly implemented in RDBMS or other NoSQL databases. Primarily, graph databases are applied in systems that share relationships between values, such as social networks, reservation systems, fraud detection, or customer relationship management systems. And graph databases address significant limitations of existing relational database management systems (RDBMS).
A graph database is a NoSQL database that organizes data as nodes, which are like records in a relational database, and relationships, which represent connections between nodes. Because the graph system stores the relationship between nodes, it can support richer representations of data relationships. Relationships are the key concept in graph databases, representing an abstraction that is not directly implemented in RDBMS or other NoSQL databases. Primarily, graph databases are applied in systems that share relationships between values, such as social networks, reservation systems, fraud detection, or customer relationship management systems. And graph databases address significant limitations of existing relational database management systems (RDBMS).
Graph databases, by design, allow simple and fast retrieval of complex hierarchical structures that are difficult to model with RDBMS. They allow for simple queries that display the nearest neighboring nodes. And they allow for complex queries that explore vast networks of connections and quickly find patterns in the connections. Flexible structure enables graph databases to accommodate complex data that doesn’t conform to rigid data models required for RDBMS implementations.
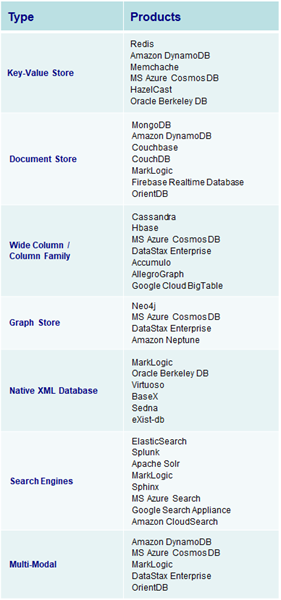
Graph databases contain four types of data fields (nodes, relationships, properties, & labels):
• Nodes: Objects that represent data entities or instances such as people, businesses, accounts, products or any other item to be tracked. They are roughly the equivalent of the record or row in a relational database, or the document in a document-store database. Each node contains several pieces of information that go together. For example, a single node might include a product name, description, price and product code. Another might have information about a customer, such as name and account number.
• Relationships: Objects that describe how the nodes relate to each other. Relationships represent the connections, edges, or lines between nodes to other nodes. A relationship connects two nodes and enables users to find related nodes. A relationship always has a source node and a target node that provides the direction of the arrow. Meaningful patterns can emerge when examining the connections and interconnections of nodes.
• Properties: Additional attributes of both nodes and relationships that are represented as additional key-value pairs. Properties store relevant data about the node or relationship with the entity it describes. Examples of priorities for a node with a label of person include name, age, address, & date of birth. Relationships usually have properties including time, distance, cost, rating or weights which are also stored as key-value pairs.
• Labels: Named graph construct that is used to group nodes into sets, and all nodes with the same label belongs to the same set. Many database queries can work with these sets instead of the whole graph, making queries easier to write and more efficient to execute. A node may be labeled with any number of labels, including none, making labels an optional addition to the graph.
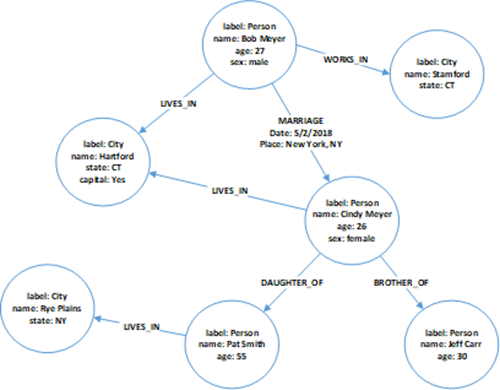
Each node in the graph database model directly and physically contains a list of relationships that represent the connections to other nodes. Unlike traditional RDBMS, graph databases do not utilize foreign keys or join operations. Instead, all relationships are natively stored within vertices.
Graph databases are purpose-built for the analysis of interconnections and relationships of data entities. This design relates well to analysis of data retrieved from social media, web, and mobile applications,. Graph databases are also useful for working with data in business disciplines that involve analyzing complex relationships and dynamic schema, such as supply chain management, customer relationship management, law enforcement intelligence, and fraud detection.


 Recently,
Recently,