Techniques of Data Warehouse Performance Optimization
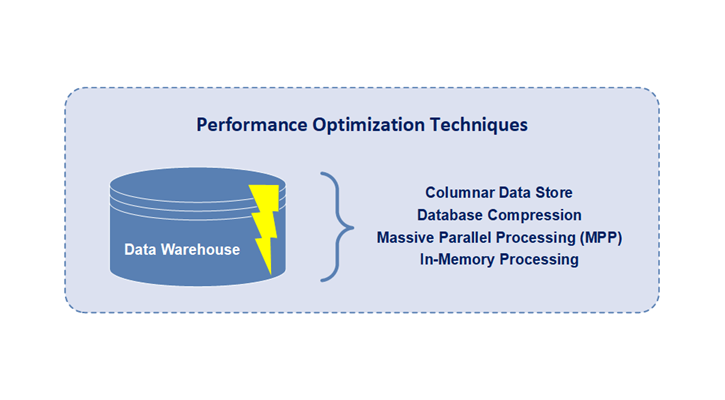
Traditionally, data warehouses are data repositories optimized for retrieval and analysis of data from transactional, legacy, or external systems, applications, and sources that provide managers, executives, and other decision makers the ability to conduct data analysis. As the main purpose of the data warehouse is the enablement of rapid querying of large and complex sets of data for data analysis, the technology needs to be designed in a way to handle this purpose. Thus, four basic techniques are now included in data warehouse technologies to enable extremely fast processing of read queries:
• Columnar Data Storage
• Database Compression
• Massive Parallel Processing (MPP)
• In-Memory Processing
Columnar Data Storage
While traditional databases store data in rows or records to limit the number of operations on data, cloud data warehouse often store data in columns or fields to increase read query performance. By storing data in columns, the database can more precisely access the data it needs to answer a query rather than scanning and discarding unwanted data in rows. Columnar data storage for database tables drastically reduces the overall number of input/output (I/O) operations to disk storage and reduces the amount of data needed to be loaded from physical disk.
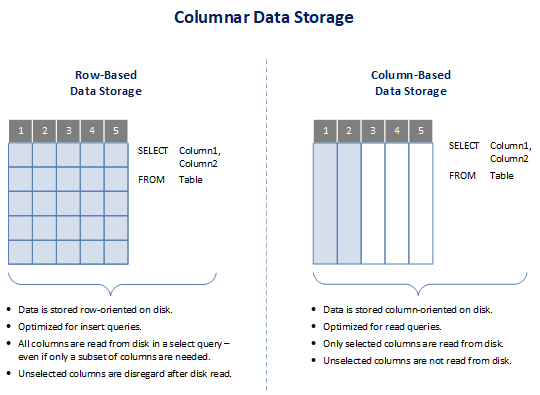
Columnar data storage data warehouse technologies ignore all the unnecessary data contained in database table rows that doesn’t apply within a read query, and only retrieves data from the selected columns of query. With columnar data storage, a database query only reads the values of columns required for processing a given query and avoids bringing into memory irrelevant fields that have not been selected within the query.
Database Compression
Data warehouses use database compression to save disk storage space by using fewer database pages to store data. Fundamentally, database compression includes a reduction in the number of bits needed to represent data. Because more data can be stored per database page, fewer database pages must be read to access the same amount of data. Therefore, queries on a compressed table need fewer disk input-output (I/O) operations to access the same amount of data and performance of read queries is increased.
In general, data warehouses have large data volumes and large amounts of data redundancy with lots of repeating values. This allows database compression to be very effective and enables very high data compression ratios (i.e. the ratio between the uncompressed size and compressed size). Generally, the higher the database compression ratio, the higher the performance gains in read queries that can be achieved.
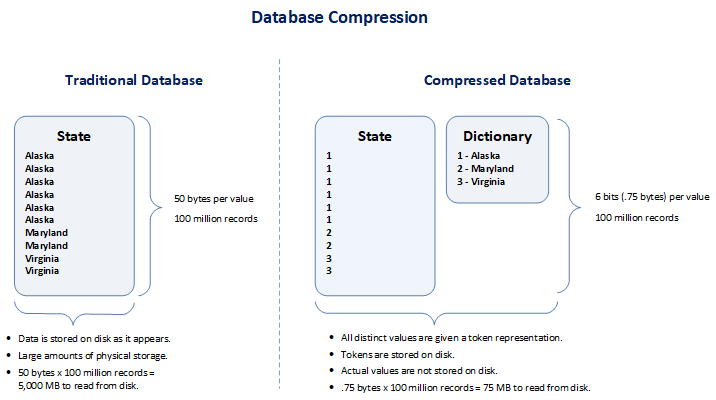
With database compression being utilized, the database can store more records per database page and fewer database pages must be read to access the same amount of data. And more data will be stored within the system buffer pool (i.e. the area of system memory that has been allocated by the database to cache table and index data). And since more data resides within the buffer pool, the likelihood that needed records are located within the buffer pool increases significantly. When a database record needs to be accessed, the related buffer is first searched, and a disk access operation can be avoided if the record is found within the buffer. By compressing records, the effective capacity of the buffer increases and consequently its hit ratio (the probability that a record will be found in buffer) increases . Thus, database compression improves query performance through improved buffer pool hit ratios.
Massive Parallel Processing (MPP)
Massive parallel processing (MPP) typically consists of independent processors, servers, or nodes that all execute in parallel and allow for optimal query performance and platform scalability. Also known as a “shared nothing architecture”, this type of data warehouse performance enhancement technique is characterized by a design in which every embedded processor or node is self-sufficient and controls its own memory and disk operations. Read queries executed against the database are broken into smaller components, and all components are worked upon both independently and simultaneously to deliver a single combined result set. Massively parallel processing refers to the fact that when a query is issued, every node works simultaneously to process the data that resides within that node. Additionally, this divide-and-conquer approach allows for massive parallel processing databases to scale linearly and perform even faster as new processors are added.
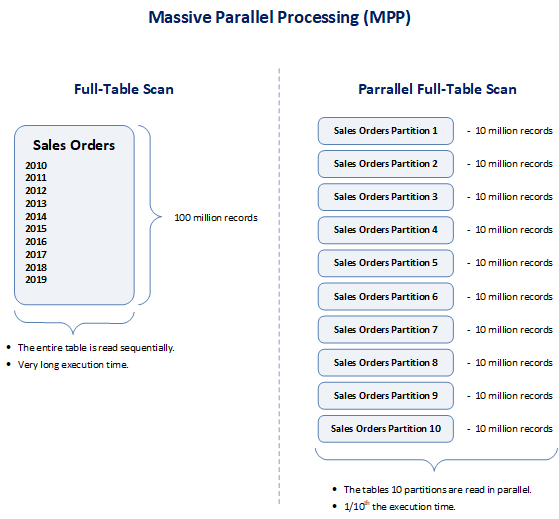
Massively parallel processing databases distribute their datasets across numerous processors, or nodes, to process large volumes of data. These nodes all contain their own storage and processing capabilities, enabling each node to execute a portion of the larger query. Massively parallel processing also refers to the fact that tables loaded into these databases are distributed across each node of a cluster, and the fact that when a query is issued, every node works simultaneously to process the data that resides within it. Fundamentally, massively parallel processing databases have been designed to execute queries in parallel over many individually processing nodes. This means that by adding more nodes to a database server, the same workload can be distributed to more processors and be completed more rapidly. Moreover, massively parallel processing databases are highly-scalable, can easily scale-up, and the addition of more nodes increases query performance.
In-Memory Processing
Data processed in the cloud data warehouse is stored within system random-access memory (RAM) rather than conventional database management system that processes data stored on physical disks. This allows the processing of queries from reads of system memory rather than reads from disk devices. Accessing data in memory eliminates both seek time and input/output (I/O) operations when querying data. Seek time is the time taken for a disk drive to locate the area on the disk where is stored. This provides faster and more predictable performance than queries conducted from data on residing on disk since retrieving data from disk storage is the slowest part of data processing. The less data that needs to be retrieved from disk, the faster the data retrieval process.
The concept behind in-memory processing is relatively simple. Traditionally, data is placed physically within a storage device known as a disk. Then, only when needed, the data is accessed from disk, moved to system memory, and acted upon within system memory. Transferring data from disk to system memory results in a bottleneck that reduces query performance. Without the bottleneck of having to access data in storage, in-memory databases can swiftly process data and convert the data into information in a highly effective way.
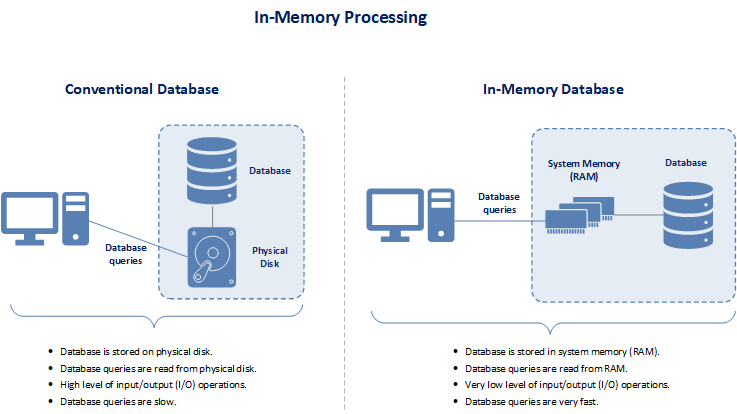
Conventional databases already have a concept known as buffer pools that caches data by storing some data within system memory. But with buffer pools, the database only caches commonly used data within system memory. In-memory processing extends the concept of caching of data way beyond the use of the buffer pools. In-memory processing caches either entire tables, indexes, or databases within system memory. And in-memory processing databases are not limited by the size of the buffer pool. In the past, in-memory processing was limited as the cost of RAM was far higher than the cost of space on disk drives. And in the past, operating systems had 32-bit architectures that could only process 4 GBs of data stored in system memory. But now the cost of RAM has come way down and operating systems now have 64-bit architectures. The means that the cost of RAM is about the same as the cost of hard disk space. And operating systems can now support 16 exabytes of system memory. The result is that large volumes of data can be stored and processed within system memory in a cost-effective manner resulting in extremely fast query execution times.