What is Machine Learning?
Machine Learning is a combined application of both data analysis and artificial intelligence that provides computer systems the ability to automatically learn and improve from experience without being explicitly programmed. The fundamental idea of machine learning is that computer systems can effectively identify patterns in data and make decisions with minimal human intervention. Moreover, machine learning focuses on discovering correlation between data elements, recognizing data patterns, and performing tasks without additional human instructions. Because machine learning often uses an iterative approach to learn from data, the learning routines and processes can be easily automated.
Fundamentally, machine learning is focused on the analysis of data for structure, even if the structure is not known ahead of time. Moreover, machine learning is focused on the implementation of computer programs and systems which can teach themselves to adapt and evolve when introduced to new data. At the core of machine learning are computer algorithms, which are procedures for solving a mathematical problem in a finite number of steps. And machine learning algorithms are utilized to build a mathematical model of sample data, known as “training data”.
Today machine learning is being used in a wide range of applications. Some common examples of how machine learning is currently being used include:
- • Social Media News Feeds and People You May Know
- • Virtual Personal Assistants / Chatbots
- • Product Recommendations / Market Personalization
- • Credit Card Fraud Detection
- • Email Spam and Malware Filtering
- • Self-Driving Car
- • GPS Traffic Predictions
- • Audio / Voice
- • Natural Language Processing / Speech Recognition
- • Financial Trading
- • Online Search
- • Healthcare
Facebook’s News Feed is one of the best examples of machine learning that has started becoming incorporated into everyday life. When a Facebook user reads, comments on, or likes a friend’s post on his personnel feed, the news feed will re-prioritize the content on user’s feeds and show more of the friend’s post and activity at the beginning of the feed. Should the member no longer read, like, or comment on the friend’s posts, the news feed will again re-prioritize the feed and will adjust the posts that appear at the begin accordingly.
A number of company websites now offer the option to chat with customer support representative while using the website. But the customer does not necessarily communicate with a live human customer support representative anymore. In many cases the customer support representative is an automated chatbot. And these chatbots are able to extract information from the website, internal database, and external data sources to present answers to customer questions. Meanwhile, chatbots get better at answering questions over time. They tend to comprehend the user questions better and respond to customers with more relevant, accurate and useful answers.
Many organizations want to gain advantage over financial markets and accurately predict market activity and fluctuations. More and more financial trading firms are using sophisticated systems to predict and execute trades at high speeds and high volume. The systems are able to predict market activity which enables effective execution of market trades (i.e. buys and sells). Computer systems have a big advantage over humans in consuming vast quantities of data and rapidly executing a large number of trades.
Categories of Machine Learning Algorithms
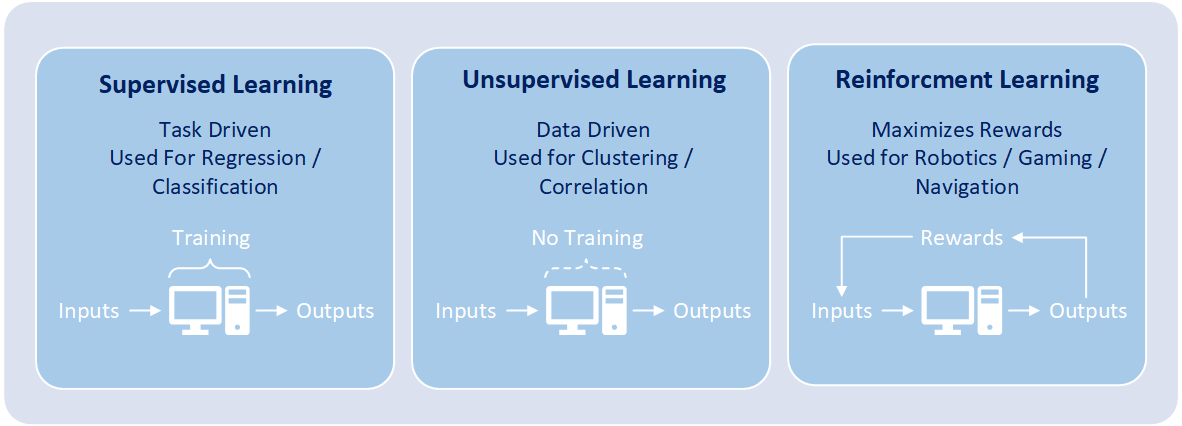
Machine learning algorithms can be divided into categories according to their purpose. The main categories of machine learning algorithms include:
1) Supervised Learning: Each algorithm is designed and trained by human data scientists with machine learning skills, and the algorithm builds a mathematical model from a data set that contains both the inputs and the desired outputs. The data scientist is responsible for determining which variables, or features, the mathematical model should analyze and use to develop predictions. A supervised learning algorithm analyzes sample or “training data” and produces an inferred function. The process of setting up and confirming a mathematical model is known as “training”. Once training is complete, the algorithm will apply what was learned to new data. Through the use of modeling techniques including classification, regression, prediction, and gradient boosting, supervised learning uses patterns to predict the values on additional data sets. Supervised learning is commonly used in applications where historical data predicts likely future events such as language recognition, character recognition, handwriting recognition, fraud detection, spam detection, and marketing personalization. Algorithms related to classification and regression utilize this category of learning.
2) Unsupervised Learning: Without setup from a human data scientist and without reference to known or desired outcomes, each algorithm infers patterns from a data set Thus the algorithm contains inputs but no previously determined outcomes. Further the algorithm utilizes an iterative approach called deep learning to review data and arrive at conclusions. Additionally, unsupervised learning algorithms are used to find structure in the data, which includes grouping, categorization, and clustering of data. Unsupervised learning algorithms work by analyzing millions records of data and automatically identifying hard to find correlations between data within the data set. These types of algorithms have only become feasible in the age of big data, as they require massive amounts of data to be useful in making predictions. Fundamentally, unsupervised learning conducts analysis on massively sized data sets, to discover useful patterns in the data, and then group the data into unique categories. The main types of unsupervised learning algorithms include clustering algorithms and association rule learning algorithms. Unsupervised learning is often used for grouping customers by purchasing behavior and correlations between purchases (i.e. people that buy X also tend to buy Y).
3) Reinforcement Learning: Through numerous iterations, the machine is trained to make the best possible decisions. The algorithm discovers through trial and error over many attempts which actions yield the greatest rewards. Steps that produce positive outcomes are rewarded and steps that produce negative outcomes are penalized. Subsequently reinforcement learning includes the sequence of decisions and acts like a game is being played. The objective of the mathematical model is for the decision-maker to choose actions that maximize the expected reward over a given amount of time. The decision-maker will most optimally reach the goal by following a good policy. And it is up to the model to determine the policy that figures out how to perform the task to maximize the reward. The policy is determined by starting from totally random trials and finishing with sophisticated tactics. Reinforcement learning is often used for robotics, gaming, and navigation.
Commonly Used Machine Learning Algorithms & Techniques
Just as there are numerous practical applications of machine learning, there are also a wide variety of algorithms and statistical modeling techniques that help enable implementations of machine learning to be effective. Some of the most commonly used algorithms for machine learning include:
1) Linear Regression: Enables the summary and study of relationships between two continuous, quantitative variables: Linear regression enables the modeling of the relationship between two variables by utilizing a linear equation (i.e. y = f(x)). One variable is considered to be an explanatory variable, and the other is considered to be a dependent variable. Linear regression is one of the most basic ways of conducting statistical modeling and is typically one of the first ways that is utilized.
2) Logistic Regression: Analyzes data in which there are one or more independent variables that determine an outcome. The outcome is measured with a binary or dichotomous variable (usually in the format of 0 and 1). Logistic regression focuses on estimating the probability of an event occurring based on the data that has been previously provided. And the goal of logistic regression is to find the best fitting model to describe the relationship between the dichotomous dependent variable and a set of independent variables.
3) Decision Trees: Uses observations about certain actions and identifies an optimal path for arriving at a desired outcome. Decision trees model decisions and their possible consequences in a binary tree-like format with two conditions for each decision. A decision tree is a flowchart-like structure that enable analysis to go from observations about an item to conclusions about the item’s target value. Observations are represented in the branches while conclusions are represented in leaves. The paths from tree root to individual leaves represent classification rules.
4) Classification and Regression Trees (CART): Two similar ways of conducting an implementation of decision trees. Rather than using a statistical equation, a binary tree-structure is constructed and is used to determine an outcome. Classification trees are used when the predicted outcome is the grouping of data to which the data belongs. Regression tree are used when the predicted outcome contains a numeric or real number value (e.g. the price of a car, salary amount, value of a financial investment).
5) K-Means Clustering: Used to categorize data without previously defined categories or groups. The algorithm works by finding groups with similar characteristics within the data, with the number of groups represented by the user-defined variable K. And the groups of data are known as clusters. The modeling technique then works in an iterative manner to assign each data point to one of K clusters.
6) K-Nearest Neighbors (KNN): Estimates how likely a data point is to be a member of one group or another. Predictions are made for a data point by searching through the entire data set to find the K-nearest groupings of data with related characteristics to the data point. The groupings of data with related common characteristics that are similar to the characteristics of the data point are known as neighbors. The value of K is user-specified and a similarity measure or distance function is used to determine how close neighbors are to each other.
7) Random Forests: Combine multiple algorithms to generate better results for classification and regression. Each individual classification is fairly weak. But much stronger with more accurate results when combined with other classifications. Random forests include a decision tree that incorporates random selections. Each tree is constructed using a random sample of records and each split is constructed using a random sample of variables. The number of variables to be searched at each split point is user-specified.
8) Naive Bayes: Classifies every value as independent of any other value and is based upon the Bayes theorem of calculating probability. Further, the algorithm enables a classifications or groupings of data to be predicted, based on a given set of variables and probability. A Naive Bayesian model is fairly easy to build, with no complicated iterative parameter estimation. It is particularly useful for very large data sets.
9) Support Vector Machine (SVM): A method of classification in which data values are plotted as points on a graph. The value of each feature of the data is then identified with a particular coordinate on a graph. SVM includes the construction of hyperplanes on a graph which assists in the identification of groupings of data, relationships between data, and data outliers.
10) Neural Networks: Loosely designed on the human brain and includes the sophisticated ability to recognize patterns. Neural networks utilize large amounts of data to identify correlations between many variables. Moreover, neural networks possess the ability the to learn how to process future incoming data. The patterns that neural networks recognize are numerical and contained in vectors. And vectors are the mathematical translation of all real-world data including voice, graphics, sounds, video, text, and time. Neural networks are very effective in learning by example and through experience. They are extremely useful for modelling non-linear relationships in data sets and when the relationship among the input variables is difficult to determine.